
Biotechnology and pharmaceutical companies have always been of interest to me. In the just the past few months, a new drug doubled the length of survival for pancreatic cancer patients and AI is being used to find new drug ideas faster to cure cardiorenal and kidney disease. Pretty cool, right?
Advancements like these are constantly happening, and a sharp increase in partnerships, funding, and acquisition are helping to fuel the industry—especially as they recover from an era of tariffs, funding cuts, and economic turndown.
While there is an optimistic view of the industry at large, I am personally more interested in the varied individual performance of firms and the progress of their developments. The effectiveness of a treatment, as reflected in clinical data, can have a large impact on the price of a stock when published. These clinical trial results often hold key insights into understanding the development of a treatment, influencing future results and equity pricing. However, the tedious part of finding valuable biotech/pharma companies to invest in is sifting through the thousands of clinical trials and deciphering dense research results. This is especially true for individual investors without access to teams of industry experts or specialized knowledge.
The need to compile large amounts of data, analyze it, and compile an investment thesis presents a great opportunity to use agentic tools powered by LLMs.
LLM tools are already being to read clinical notes and synthesize evidence in clinical trials, and the capabilities they have continue to improve.
To take advantage of these new methods, I created a fairly trivial solution running on a local web app. The core purpose it so help the user investigate upcoming clinical-trial catalysts without relying on a single source or a shallow summary. It gathers trial data, supporting literature and current discussion, and turns everything into a report of information that is easier to build an investment thesis or further research on.
The program begins by pulling in upcoming clinical trials from ClinicalTrials.gov. After selecting one, it builds a research workflow around that trial. The phase, sponsor, endpoints, and timing all shape what evidence is relevant, and impact how the research workflow is built.
The research pipeline pulls from several sources. It queries PubMed and Europe PMC for clinical literature, GDELT and Google News RSS for current coverage, social media for market discussion, and finally a browser-based web search layer for broader scraping beyond the explicit source list as needed by the agents. The goal is to assemble evidence that helps answer important questions: What is the trial trying to prove? What would success look like? What are likely failures? What prior evidence supports or weakens the case?
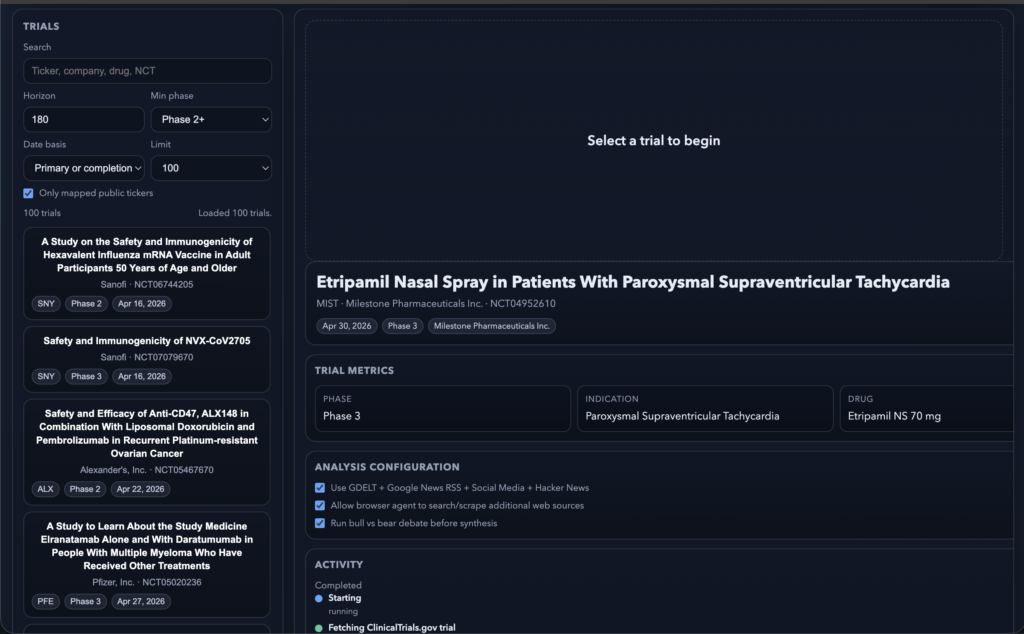
The program cycles between LLM models, using the more powerful (yet more expensive) models for substantive analysis, and lighter models for extracting data and web searches. This creates a fairly efficient workflow, taking only 10 minutes and often costing <$1.
All this data is stored in a local database for future analysis, which also allows the user to reference the primary sources so the analysis can be checked against the evidence.
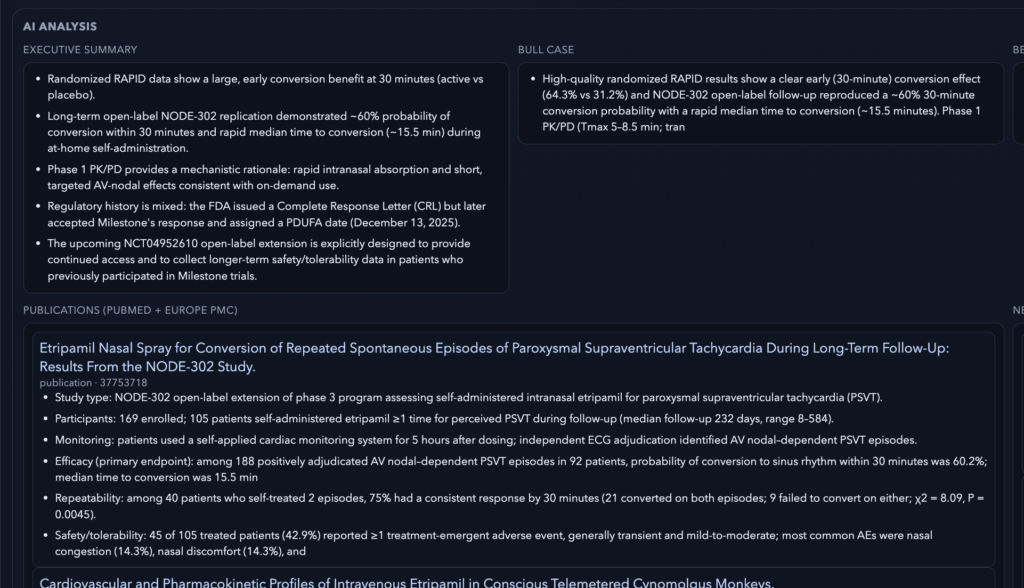
The output is structured around a investment research frame. It produces a bull case, bear case, unknowns, and what to watch. That makes the tool more useful for actual decision-making because it surfaces uncertainty explicitly. It also avoids the main weakness of generic AI summaries, which often compress important caveats into a single confident paragraph. When analysis is complete, the app presents the result in a structured dashboard and renders a knowledge graph linking concepts to citations, helping users understand how the analysis connects to the gathered evidence.
So… how effective is this tool?
Let’s start with the good news. These LLM agents are great at finding and compiling vast amounts of information. They are able to parse through PubMed and pull out dozens of relevant studies, read hundreds of social media comments, and independently search the web for any gaps in information. All of this done in just a few minutes, saving potentially hours of manual work. They are also good at extracting key metrics from these articles, and seeing generalized trends across them.
However, these models still do not have a high enough intellectual capability needed for deeper analysis, and are not well equipped to manipulate the data presented in these trial results to create novel understandings. They may also miss nuances in the data, and get distracted by existing bias’ in the results. Despite this, the growth in model intelligence is staggering, and I expect results to improve in the coming months.
This project can be improved in many ways. Using more powerful models, adding more agents (particularly for high-level supervision), allowing human input to shape research, and providing tools to the agents can all be implemented to improve results.
Through this project, I learned a lot about building independent agents and using them in equity research. It is clear that they present a large opportunity for improving efficiency, so long as current limitations are considered. I look forward to building on this framework, and using it in my own investing.
-Zach